
a cura di Giacomo Milazzo

«Dopo le prime pagine sentirete le sinapsi rafforzarsi. Alla fine avrete raggiunto la vostra personale forma di deep learning – con profondo piacere».
Innanzi tutto abbiate pazienza. Arriverete infine al cap. 12, l’ultimo, il più bello forse, affascinante e facile da seguire e all’Epilogo, con i risvolti positivi e negativi di questa materia di grandissima attualità. E tutte quelle formule viste fino ad allora, vi appariranno chiare, come quelle due o tre sessioni di approfondimento matematico presenti nel libro, evitabili per dirla con l’Autore, lasciando ben impressi i concetti a premiare l’Autore per aver avuto il coraggio di presentare formule ed equazioni: ma non spaventatevi, è matematica necessaria, ma da scuola superiore e anche se mancasse, come al sottoscritto, l’elasticità mentale di un liceale, ve la caverete benissimo.
Perché un libro del genere sulle nostre pagine? Perché no? Forse occorre colmare una piccola lacuna, ma spesso ben percettibile, che aleggia nel profondo cuore naturalistico che è alla base della geologia e delle scienze ambientali. E viaggiare in spazi dalle dimensioni inimmaginabili è vivere un’avventura. Ma soprattutto, come evidenziato nella precedente recensione del libro di Quattrociocchi e Cinelli, perché intorno all’Intelligenza Artificiale (AI, con l’acronimo inglese), soprattutto a seguito dell’esplosione dei chatbot come ChatGPT, c’è una profonda confusione, chiacchiere da bar e sproloqui metafisici!
Materia di attualità si diceva. Non a caso la seconda prova scritta per i maturandi 2025 degli Istituti Tecnici Informatici riguardava proprio l’AI: approfondire concetti come machine learning e deep learning, con particolare attenzione alle loro applicazioni nel contesto della classificazione di dati e informazioni, e un caso da risolvere: progettare un sistema di identificazione e classificazione di notizie, distinguendo le vere dalle fake news, e perché no, anche quelle dubbie. Vale la pena dare un’occhiata al testo originale qui.
Insomma proprio quanto viene trattato in questo libro fin dal primo capitolo. Cercare un modello con un sistema di apprendimento supervisionato, che possa magari imparare dai suoi stessi errori. È solo un esempio: classificare le notizie per tipologia (blog, social media, giornale online, piattaforma di streaming…) e fonte (New York Times, Gazzetta del Mezzogiorno, Focus, Facebook, Instagram, TikTok, Spotify, YouTube, Geologia dell’Ambiente…). Ogni notizia è inoltre caratterizzata da un URL che la localizza sul web, una data di pubblicazione, un eventuale titolo, l’autore se disponibile, il contenuto testuale (derivante da un articolo di giornale, un post su un social, o la trascrizione di un video o di un podcast, ecc.); e ad essa possono essere eventualmente associati più contenuti multimediali (audio, video e immagini) ed anche più commenti che possono accompagnare la notizia. Sembra mostruosamente complicato, dozzine di ingressi con pesi diversi e un’unica uscita: vero o falso. E questo è niente in confronto alle reti neuronali (informatiche ovviamente) dotate di centinaia di migliaia di miliardi di parametri che stanno dietro e caratterizzano quanto ormai per molti, e spesso in malo modo, è diventato strumento pressoché quotidiano, come le interfacce ChatGPT di OpenAI, Gemini di Google, o Bing, Copilot di Microsoft o Perplexity, uno degli ultimi arrivati.
Se oggi chiedessimo alla gente cosa sia l’AI probabilmente risponderebbe “ChatGPT”: non è così. L’intera storia dell’apprendimento automatico risale a molto tempo fa, e nel frattempo sono successe molte altre cose. Come spesso accade, il fenomeno AI, sconosciuto fino a pochi anni fa persino a chi lavorava nel settore informatico, sembra ci stia travolgendo, soprattutto nel nostro paese che storicamente non ha saputo capire e cogliere per tempo le due grandi rivoluzioni informatico-tecnologiche passate, arrivando con grande ritardo: quella del Personal Computer negli anni Ottanta e quella di Internet negli anni Novanta del XX secolo. Rischio che stiamo correndo anche adesso liquidandolo con etichette semplicistiche e dimenticando che quelle rivoluzioni, e questa in atto, hanno permesso ad esempio alla sola California, di superare il PIL della Germania o del Giappone.
Un fenomeno, questo dell’AI, che va capito piuttosto che accettato o rifiutato a priori, soprattutto perché l’AI non è ancora sicura per permetterne l’uso in applicazioni rischiose, come quelle del settore medico o farmacologico, pur essendone già in atto diverse e con successo.
 Il libro parte dal lontano 1958, quando l’8 luglio di quell’anno il New York Times riportava una notizia piuttosto straordinaria. Il titolo recitava: «Un nuovo dispositivo della Marina Militare impara agendo: uno psicologo mostra l’embrione di un computer progettato per leggere e diventare più saggio». Il paragrafo di apertura alzava ulteriormente la posta in gioco: «La Marina ha rivelato oggi l’embrione di un computer elettronico che si prevede sarà in grado di camminare, parlare, vedere, scrivere, riprodursi ed essere consapevole della propria esistenza». Con il senno del poi, l’iperbole è ovvia e imbarazzante ma il giornale non aveva tutte le colpe. Era stato annunciata da poco l’invenzione del perceptron (o percettrone) che, secondo l’autore sarebbe stato il «primo dispositivo a pensare come il cervello umano» e avrebbe potuto essere inviato su altri pianeti come «esploratore spaziale meccanico». Nulla di tutto ciò accadde ma, molto più seriamente di quel che sembra, quelle ricerche aprirono la strada che ha portato al momento storico che stiamo vivendo, con l’arrivo dei cosiddetti Large Language Model (LLM), come ChatGPT e i suoi simili, un vero e proprio boom tecnologico.
Il libro parte dal lontano 1958, quando l’8 luglio di quell’anno il New York Times riportava una notizia piuttosto straordinaria. Il titolo recitava: «Un nuovo dispositivo della Marina Militare impara agendo: uno psicologo mostra l’embrione di un computer progettato per leggere e diventare più saggio». Il paragrafo di apertura alzava ulteriormente la posta in gioco: «La Marina ha rivelato oggi l’embrione di un computer elettronico che si prevede sarà in grado di camminare, parlare, vedere, scrivere, riprodursi ed essere consapevole della propria esistenza». Con il senno del poi, l’iperbole è ovvia e imbarazzante ma il giornale non aveva tutte le colpe. Era stato annunciata da poco l’invenzione del perceptron (o percettrone) che, secondo l’autore sarebbe stato il «primo dispositivo a pensare come il cervello umano» e avrebbe potuto essere inviato su altri pianeti come «esploratore spaziale meccanico». Nulla di tutto ciò accadde ma, molto più seriamente di quel che sembra, quelle ricerche aprirono la strada che ha portato al momento storico che stiamo vivendo, con l’arrivo dei cosiddetti Large Language Model (LLM), come ChatGPT e i suoi simili, un vero e proprio boom tecnologico.
 La risposta a questo fenomeno, che alcuni hanno paragonato a ciò che accadde nel primo ventennio del XX secolo, quando i fisici si dovettero confrontare con la stravaganza della meccanica quantistica, ha le sue radici nella ricerca iniziata da Frank Rosenblatt, psicologo e ingegnere della Cornell University, inventore del percettrone.
La risposta a questo fenomeno, che alcuni hanno paragonato a ciò che accadde nel primo ventennio del XX secolo, quando i fisici si dovettero confrontare con la stravaganza della meccanica quantistica, ha le sue radici nella ricerca iniziata da Frank Rosenblatt, psicologo e ingegnere della Cornell University, inventore del percettrone.
Questo libro entra a fondo nei particolari tecnici di ogni argomento trattato (si veda qui per un dettaglio sull’indice degli argomenti) affrontando i dettagli tecnologici. Spiega l’elegante matematica e gli algoritmi che, per decenni, hanno stimolato ed entusiasmato i ricercatori nel campo dell’apprendimento automatico, il machine learning (ML), un tipo di AI che prevede la costruzione di macchine in grado di imparare a individuare modelli nei dati, senza essere esplicitamente programmate per farlo: macchine che, opportunamente addestrate, possono rilevare modelli simili in un nuovo insieme di dati (dataset), rendendo possibili applicazioni che vanno dal riconoscimento delle immagini alla realizzazione, almeno potenzialmente, di auto completamente autonome e altre tecnologie ancor più futuristiche. E ancora, per entrare – un po’ forzatamente, lo ammetto – in un tema a me molto caro, interrogarsi sulla reazione di molti climascettici che rifiutano le conclusioni dei climatologi perché, dicono, sono solo modelli. Chissà cosa penserebbero se sapessero che la matematica che c’è dietro quei modelli è, in definitiva, spesso la stessa che c’è dietro il software del navigatore, o dietro i processi di lettura degli audiolibri, dei traduttori automatici, del riconoscimento facciale, del sistema di sicurezza e controllo della guida ormai a disposizione anche sulle utilitarie?
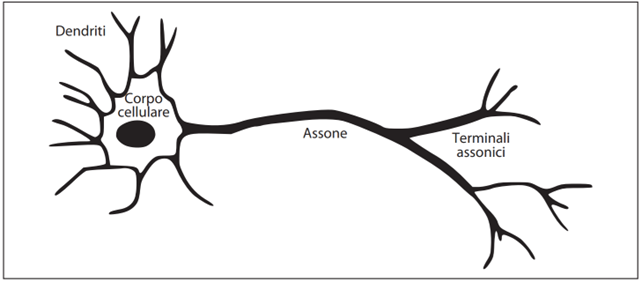
 Le macchine possono imparare grazie alla straordinaria sinergia fra matematica e informatica, con l’aggiunta di un pizzico di fisica e neuroscienza, quest’ultima in apertissimo dibattito – spesso puramente speculativo e condotto da cultori della metafisica – e ricerca di analogie, per ora introvabili, tra reti neurali informatiche e reti biologiche.
Le macchine possono imparare grazie alla straordinaria sinergia fra matematica e informatica, con l’aggiunta di un pizzico di fisica e neuroscienza, quest’ultima in apertissimo dibattito – spesso puramente speculativo e condotto da cultori della metafisica – e ricerca di analogie, per ora introvabili, tra reti neurali informatiche e reti biologiche.
L’apprendimento automatico (ML) è un campo vasto, popolato da algoritmi che fanno leva su una matematica relativamente semplice che risale a secoli fa, una matematica che si impara alle scuole superiori o all’inizio dell’università: algebra elementare, calcolo infinitesimale, calcolo vettoriale e un pizzico di matriciale. Ma anche statistica, come quella del lavoro di Thomas Bayes e del suo omonimo teorema: un contributo fondamentale nel campo della probabilità e della statistica. Senza dimenticare Gauss e le sue distribuzioni. E poi c’è l’algebra lineare, che costituisce la spina dorsale del machine learning. La prima esposizione di questa branca della matematica è contenuta in un testo cinese di duemila anni fa. Forse qualcuno non troverà particolarmente eleganti queste aree della matematica ma, una volta messe insieme, come le dimostrazioni che ne conseguono, lo diventano sicuramente, pur consci che eleganza e bellezza sono concetti soggettivi.
 Questo libro racconta la storia di un viaggio straordinario, dal perceptron di Rosenblatt alle moderne “reti neurali profonde” o “deep neural network” (composte da unità computazionali chiamate “neuroni artificiali”), attraverso la lente di ingrandimento delle idee matematiche che sono alla base del campo dell’apprendimento automatico.
Questo libro racconta la storia di un viaggio straordinario, dal perceptron di Rosenblatt alle moderne “reti neurali profonde” o “deep neural network” (composte da unità computazionali chiamate “neuroni artificiali”), attraverso la lente di ingrandimento delle idee matematiche che sono alla base del campo dell’apprendimento automatico.
Abbracciando senza timore equazioni e concetti provenienti da almeno quattro grandi campi della matematica, algebra lineare, calcolo infinitesimale, probabilità/statistica e teoria dell’ottimizzazione, si acquisiranno le conoscenze teoriche e concettuali minime necessarie per apprezzare l’impressionante potere che stiamo conferendo alle macchine. Solo quando avremo compreso
l’inevitabilità del machine learning saremo pronti ad affrontare un futuro in cui l’AI sarà onnipresente, nel bene e nel male. Abbiate pazienza, scrivevo all’inizio, ne vale la pena.
Capire la matematica dell’apprendimento automatico è fondamentale per capire non solo la potenza della tecnologia, ma anche i suoi limiti. I sistemi di machine learning stanno già prendendo decisioni che ci cambiano la vita: approvano le carte di credito e i mutui ipotecari, determinano lo stadio di avanzamento di un tumore, stabiliscono la prognosi di una persona in declino cognitivo (si ammalerà di Alzheimer?) e decidono se concedere la libertà provvisoria a qualcuno. L’apprendimento automatico sta permeando anche la scienza: sta influenzando la chimica, la biologia, la fisica e tutto il resto. Viene utilizzato nello studio dei genomi, dei pianeti extrasolari, delle complessità dei sistemi quantistici e molto altro ancora.
E, tuttora, il mondo dell’AI è in fermento per le conseguenze inattese che i modelli linguistici (LLM), come ChatGPT, stanno dimostrando di avere sviluppi (non intenzionali! si badi bene…) che lasciano spesso stupiti i loro stessi ideatori. Ma attenzione, non stanno né hanno imparato a ragionare, anche se riescono ad imitare questa caratteristica esclusiva del genere umano e forse di qualche primate: è solo che, a quanto pare, all’occhio del profano o del troppo entusiasta positivista, mancano le conoscenze sulla matematica di base che sta dietro questi risvolti pratici. La palla è stata appena lanciata.
Non possiamo però lasciare solo ai suoi ideatori le decisioni sul modo in cui l’AI sarà costruita e impiegata. Se vogliamo regolamentare efficacemente questa tecnologia estremamente utile, ma dirompente (disruptive, i tecnologi americani usano il termine in senso positivo) ma potenzialmente minacciosa, anche altri strati della società (educatori, legislatori, comunicatori scientifici e perfino i semplici utilizzatori dell’AI) devono affrontare la matematica alla base dell’apprendimento automatico.
Fortunatamente, il disagio intellettuale che la matematica provoca in molti, e attende i lettori di questo libro, è facilmente sopportabile e più che compensato dal guadagno intellettuale, perché, ripetiamolo, alla base del moderno ML c’è una matematica relativamente semplice ed elegante, spiegabile a degli studenti senza troppi sforzi.
Questo libro vuole raccontare la semplicità concettuale che sta alla base del machine learning e del deep learning. Non vuol dire, però, che tutto quello che stiamo vedendo oggi nell’AI, in particolare il comportamento delle deep neural network e dei large language model, sia analizzabile con una matematica semplice.
In realtà, l’epilogo di questo libro ci porta in un luogo che alcuni potrebbero trovare sconcertante, mentre altri lo troveranno esaltante: le reti neurali e l’AI stessa sembrano ignorare alcune delle idee fondamentali che per decenni sono state alla base dell’apprendimento automatico. È come se l’evidenza empirica avesse fatto irruzione nel campo teorico, nello stesso modo in cui le osservazioni sperimentali del mondo naturale, all’inizio del ventesimo secolo, sconvolsero la fisica classica. Anche se in molti si limitano per ora a realizzare algoritmi e modelli che funzionano senza chiedersene il perché, la matematica che serve deve ancora venire, qualcosa di nuovo per dare un senso all’incredibile mondo che ci aspetta.
Le moderne reti neurali artificiali imparano e lo fanno ad ogni passaggio che l’algoritmo effettua sui dati: imparano qualcosa in più sugli schemi che esistono in tali dati. Un solo passaggio può non essere sufficiente, né dieci, né cento. A volte le reti neurali imparano dopo decine di migliaia di iterazioni sui dati a loro disponibili. Lo stesso vale per l’apprendimento che questo libro ci offre. Le cose che non hanno senso la prima o la seconda volta, con i passaggi successivi lo acquisiscono. Ecco perché l’Autore ripete a volte idee e concetti, a volte con la stessa identica formulazione, o sfruttando una diversa interpretazione del medesimo concetto: per aiutare i lettori a creare dei collegamenti simili. Ripetizioni e riformulazioni intenzionali: rappresentano un modo con cui la maggior parte di noi, che non siamo matematici o specialisti di ML, ci avviciniamo a un argomento teoricamente semplice, ma a prima vista complesso. Una volta esposta un’idea, il nostro cervello può scorgere degli schemi e creare delle nuove connessioni quando incontra altrove quella stessa idea, dandole più senso di quanto ne aveva a prima vista.
Un altro aspetto emerge importante dalla lettura di questo libro. Non possiamo lasciare la realizzazione di questi sistemi AI solo ai professionisti, solo alle persone che li stanno costruendo oggi. Abbiamo bisogno di più persone nella nostra società, che siano comunicatori scientifici, giornalisti, responsabili politici, utenti realmente interessati della tecnologia, ma che abbiano quel minimo di conoscenze matematiche, o che abbiano voglia di acquisirle, che consentano loro di dare un senso al motivo per cui le macchine imparano, per essere in grado di apprezzare e soprattutto gestire il potere crescente che stiamo dando a queste soluzioni, il loro potere, che viene dagli algoritmi che progettiamo e dalla matematica che li fa funzionare, ma soprattutto i loro limiti: e ciò avviene solo quando questa matematica è stata compresa a dimostrarci che queste macchine non stanno ragionando ma che ciò che sta accadendo in questo momento è che queste macchine stanno facendo una correlazione estremamente sofisticata, ma che può accadere che la sofisticazione, la complessità dei modelli alla base, generi una sorta di allucinazione, risultati che non seguono uno schema identificabile, che non hanno nulla a che fare con i dati di addestramento, o che produca un’illusione di ragionamento, di realtà. Gli LLM come ChatGPT il più delle volte danno risposte giuste, ma è quella volta che è sbagliata ad avere importanza.
Anche se in realtà il termine allucinazione è stato spesso usato in modo colloquiale solo quando gli LLM sbagliano, in realtà, se si guarda al modo in cui funzionano gli LLM, tutto ciò che stanno facendo è essenzialmente un’allucinazione, un’illusione di realtà. E penso che quei termini perdano davvero di significato non appena si capisce che è così che funzionano. Essenzialmente, gli viene dato un pezzo di testo e si attivano nella selezione e nella ricerca della parola successiva più probabile che segua quel testo. Aggiungono quella parola al pezzo di testo originale, e partono a prevedere la prossima parola più probabile e poi la prossima parola più probabile, e così via fino a quando non producono qualcosa che ritengono sia il testo finito, e tutto si ferma. Quindi, in ogni fase, è essenzialmente un’affermazione probabilistica su quale sia la parola più probabile che segua il testo che dato. Non importa se la risposta è giusta o sbagliata. Il processo è sempre lo stesso. Quando un LLM è abbastanza grande, queste probabilità generate internamente al fine di fare la migliore ipotesi su ciò che dovrebbe venire dopo, migliorano sempre di più e quindi le risposte possono iniziare a sembrare ragionate, addirittura pensate! Ma il processo, sia che si sbagli o che si stia facendo bene, è sempre lo stesso, e assolutamente generato artificialmente, nessuna entità né agentività dietro!
Quindi, dato che stanno usando lo stesso processo, questa cosiddetta illusione di realtà, per trovare risposte che siano giuste o sbagliate, è davvero difficile sapere quando le risposte che stanno producendo sono corrette e quando sono sbagliate. E si genera qualcosa di contraddittorio: diventa quasi necessaria la conferma di un esperto umano per essere in grado di esaminare quanto un LLM ha prodotto.
Gli LLM non sono gli unici modelli di AI, ce ne sono altri, e anche se trattati meno approfonditamente sono illustrati nel libro e, meno strano di quel che sembra sono certo che qualcuno di voi troverà dei riscontri col lavoro di Frances Arnold, che è stato raccontato nel libro di Telmo Pievani “Tutti i mondi possibili”, da me recensito.
Abbiate pazienza, e spero che ai vostri neuroni questo libro sarà gradito tanto quanto è piaciuto ai miei.
Anil Ananthaswamy

Anil Ananthaswamy è uno scrittore scientifico pluripremiato, ex redattore e vicedirettore della rivista londinese New Scientist . È stato borsista del MIT Knight Science Journalism per il 2019-20 . È stato guest editor per il programma di scrittura scientifica dell’Università della California, Santa Cruz, e organizza e tiene un workshop annuale di scrittura scientifica presso il National Centre for Biological Sciences di Bengaluru, in India. È redattore freelance per PNAS Front Matter . Scrive regolarmente per New Scientist, Quanta , Scientific American, PNAS Front Matter e Nature, e ha collaborato, tra gli altri, con Nautilus, Matter , il Wall Street Journal, Discover e la rivista britannica Literary Review.
“La soglia che non c’è”
“È solo statistica!”
Un’interessante serie di brevi interventi
di Walter Quattrociocchi (Data Science, Network Science, Complex Systems, Full Professor at Department of Computer Science Sapienza University of Rome)
Nota. Le pagine Facebook pubbliche sono accessibili anche senza account. È sufficiente chiudere la richiesta di accesso.
Qualcosa di inaspettato
A book review
Contributi video dell’Autore
Video divulgativi di natura tecnica